
Analisi della frequenza delle lettere
Uno dei sistemi più utilizzati per la crittoanalisi di testi cifrati, specie quelli della famiglia dei metodi a sostituzione, è proprio l'analisi della frequenza con cui si ripetono alcune lettere in una data lingua.
Analizzando come esempio, un testo scritto in italiano, anche di lunghezza limitata, noteremo sicuramente che le lettere che compaiono con più frequenza, sono nell'ordine: e,i,a,o. Questa caratteristica può essere sfruttata per decrittare cifrati sconosciuti, o perlomeno come validissima informazione iniziale per la crittoanalisi.
Nell'area download di questo sito, è presente un programma gratuito di nome FindFreq, realizzato per l'occasione. Con tale programma si possono individuare le frequenze in formato numerico e grafico. Utilizzando tale programma su diversi testi italiani si può verificare quanto esposto qui di seguito.
Come esperimento è stato analizzato un file di testo di nome rasread.txt, un file presente nel sistema operativo Windows NT 4. Trattasi di un testo italiano contenente 46.318 caratteri dell'alfabeto. Le frequenze rilevate per ogni singola lettera sono:
A=8,48%; B=0,64%; C=4,3%; D=4%; E=11,96%; F=0,95%; G=1,28%; H=0,73%; I=11,43%; J=0,02%; K=0,16%; L=5,75%; M=2,68%; N=7,57%; O=8,48%; P=3,18%; Q=0,3%; R=7,31%; S=6,67%; T=6,43%; U=3,33%; V=1,57%; W=8,88%; X=0,23%; Y=0,14%; Z=1,53%
La visualizzazione grafica delle frequenze su tale testo è la seguente:
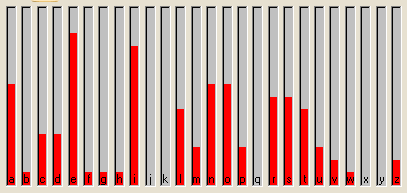
Proviamo ad analizzare un altro testo: un corso per Windows. In questo caso le lettere dell'alfabeto nel testo, sono oltre 114.000, quindi le lettere più frequenti si innalzano ancora di più rispetto alle altre (il programma offre la possibilità di zoomare e questa visualizzazione è stata effettuata a 7x onde far risaltare meglio i risultati). Si può comunque notare che l'ordine delle frequenze resta invariato.
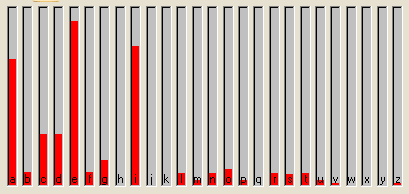
A dimostrazione di quanto sopra, proviamo a tagliare a metà il file contenente il testo appena esaminato.
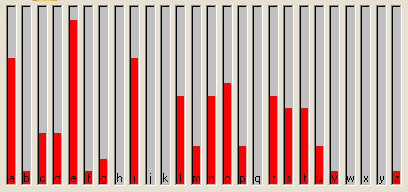
Come si può notare, con un totale di 50.000 caratteri siamo tornati ad una situazione simile all'analisi del testo rasread.txt che ne contiene poche migliaia in meno.
Come sfruttare questo programma e l'analisi statistica per decrittare un testo cifrato?
Analizzando un qualsiasi testo italiano, inglese, ecc. è possibile stabilire per conto proprio quale sono le frequenze di ogni lettera dell'alfabeto in tale lingua. Analizzando poi le frequenze di un testo cifrato, si può capire con quale lettera è stata sostituita, associando la frequenza di ogni singola lettera del testo cifrato, con quella dell'alfabeto di tale lingua (che andrà scoperta per tentativi se non conosciuta). Se ad esempio in un testo che sappiamo essere italiano, spicca come lettera a frequenza più alta la lettera "x", sicuramente tale lettera deve essere sostituita con la lettera "e". Operando la sostituzione di tutte le lettere del testo cifrato secondo questo schema, il testo sarà decrittato come minimo al 60%. Ciò significa che ci troveremo ad avere un testo con lettere mancanti o errate in ogni parola, ma facilmente immaginabili. Più il testo crittato è lungo, maggiore sarà la percentuale di successo. Su testi da oltre 40.000 caratteri, la decifratura è praticamente, automaticamente completa. Può comunque essere un ottimo esercizio per partecipare all Ruota della Fortuna con Mike Bongiorno!
Ovviamente con gli algoritmi polialfabetici, sebbene siano metodi a sostituzione, le cose si complicano molto rispetto all'analisi di un monoalfabetico creato, ad esempio, con il cifrario di Cesare. Con i metodi monoalfabetici questo sistema di crittoanalisi porta alla soluzione in un batter d'occhio (a meno che non sia stato utilizzato anche un nomenclatore o un dizionario, mentre con i polialfabetici si può operare solo a blocchi di lunghezza pari alla chiave, dato che dopo tale lunghezza l'alfabeto di sostituzione varia. In questi casi conviene utilizzare la crittoanalisi lineare o differenziale.